SGLang:高并发推理优化框架
本教程内容已封装为
sglang_0.4.6.post5_3.10.16-ubuntu22.04_12.6镜像。若您使用该镜像创建云主机,可以在云主机启动完成后登录实例,通过本地直接启动sglang服务:conda activate SGLang python3 -m sglang.launch_server --model-path /root/.cache/modelscope/hub/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --port 8890 --mem-fraction-static 0.7 --tp 1 --trust-remote-code --host 0.0.0.0conda activate SGLang python3 -m sglang.launch_server --model-path /root/.cache/modelscope/hub/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --port 8890 --mem-fraction-static 0.7 --tp 1 --trust-remote-code --host 0.0.0.0sglang 服务运行在内部端口
8890。在云主机的【更多连接方式】→【预留端口】,您可通过IP及内部端口映射的公网端口实现对外访问。
幕僚算力虚机参数
- 镜像:conda3_25.1.1_3.10.16-ubuntu22.04_12.6
- GPU:1卡 (4090)
- 数据盘:100G(原50GB,另外扩容50GB)
修改 Miniconda 数据目录
镜像sglang_0.4.6.post5_3.10.16-ubuntu22.04_12.6中未执行此命令,已全部保存在系统盘默认存储目录中
可以使用以下命令来查看 Conda 的配置信息
conda config --show envs_dirs pkgs_dirsconda config --show envs_dirs pkgs_dirs查看输出中 envs_dirs 和 pkgs_dirs属性:
# 环境目录,当你创建新的 Conda 环境时,这些环境会被安装在上述目录里。
envs_dirs:
- /root/miniconda3/envs
- /root/.conda/envs
# 包缓存目录,在下载和安装包时,Conda 会把包文件缓存到这些目录中。
pkgs_dirs:
- /root/miniconda3/pkgs
- /root/.conda/pkgs# 环境目录,当你创建新的 Conda 环境时,这些环境会被安装在上述目录里。
envs_dirs:
- /root/miniconda3/envs
- /root/.conda/envs
# 包缓存目录,在下载和安装包时,Conda 会把包文件缓存到这些目录中。
pkgs_dirs:
- /root/miniconda3/pkgs
- /root/.conda/pkgs创建目录
mkdir -p /data/conda/envs
mkdir -p /data/conda/pkgsmkdir -p /data/conda/envs
mkdir -p /data/conda/pkgs修改 .condarc 文件
手动编辑 /root/miniconda3/.condarc 文件,添加或修改如下内容:
envs_dirs:
- /data/conda/envs
- /root/miniconda3/envs
- /root/.conda/envs
pkgs_dirs:
- /data/conda/pkgs
- /root/miniconda3/pkgs
- /root/.conda/pkgsenvs_dirs:
- /data/conda/envs
- /root/miniconda3/envs
- /root/.conda/envs
pkgs_dirs:
- /data/conda/pkgs
- /root/miniconda3/pkgs
- /root/.conda/pkgs再次运行 conda config --show 命令,确认 envs_dirs 和 pkgs_dirs 已经更新:
conda config --show envs_dirs pkgs_dirsconda config --show envs_dirs pkgs_dirs安装 SGLang
SGLang 支持多种方式的安装,这里以pip安装为例。
SGLang 官方文档:https://docs.sglang.ai/start/install.html
SGLang Github 地址:https://github.com/sgl-project/sglang
FlashInfer 安装文档:https://docs.flashinfer.ai/installation.html
# 创建虚拟环境(Python≥3.10 and <3.13)
conda create --name SGLang python=3.11 -y
conda activate SGLang
# 通过修改环境变量的方式修改pip缓存目录
# 默认在/root/.cache/pip,该目录不能扩容,所以修改到/data/下
echo 'export PIP_CACHE_DIR=/data/pip/cache' >> ~/.bashrc
source ~/.bashrc
# 验证 pip 缓存目录
pip cache dir
python3 -m pip install --upgrade pip
pip install "sglang[all]>=0.4.6.post5"
# 开启学术加速
export http_proxy=http://10.132.19.35:7890
export https_proxy=http://10.132.19.35:7890
# Install FlashInfer CUDA kernels
pip install flashinfer-python -i https://flashinfer.ai/whl/cu126/torch2.6/# 创建虚拟环境(Python≥3.10 and <3.13)
conda create --name SGLang python=3.11 -y
conda activate SGLang
# 通过修改环境变量的方式修改pip缓存目录
# 默认在/root/.cache/pip,该目录不能扩容,所以修改到/data/下
echo 'export PIP_CACHE_DIR=/data/pip/cache' >> ~/.bashrc
source ~/.bashrc
# 验证 pip 缓存目录
pip cache dir
python3 -m pip install --upgrade pip
pip install "sglang[all]>=0.4.6.post5"
# 开启学术加速
export http_proxy=http://10.132.19.35:7890
export https_proxy=http://10.132.19.35:7890
# Install FlashInfer CUDA kernels
pip install flashinfer-python -i https://flashinfer.ai/whl/cu126/torch2.6/
下载模型
访问魔塔模型库:https://www.modelscope.cn/models
搜索 “DeepSeek” ,选择一个模型测 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 下载:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
在 “模型文件” 页面,下载模型:
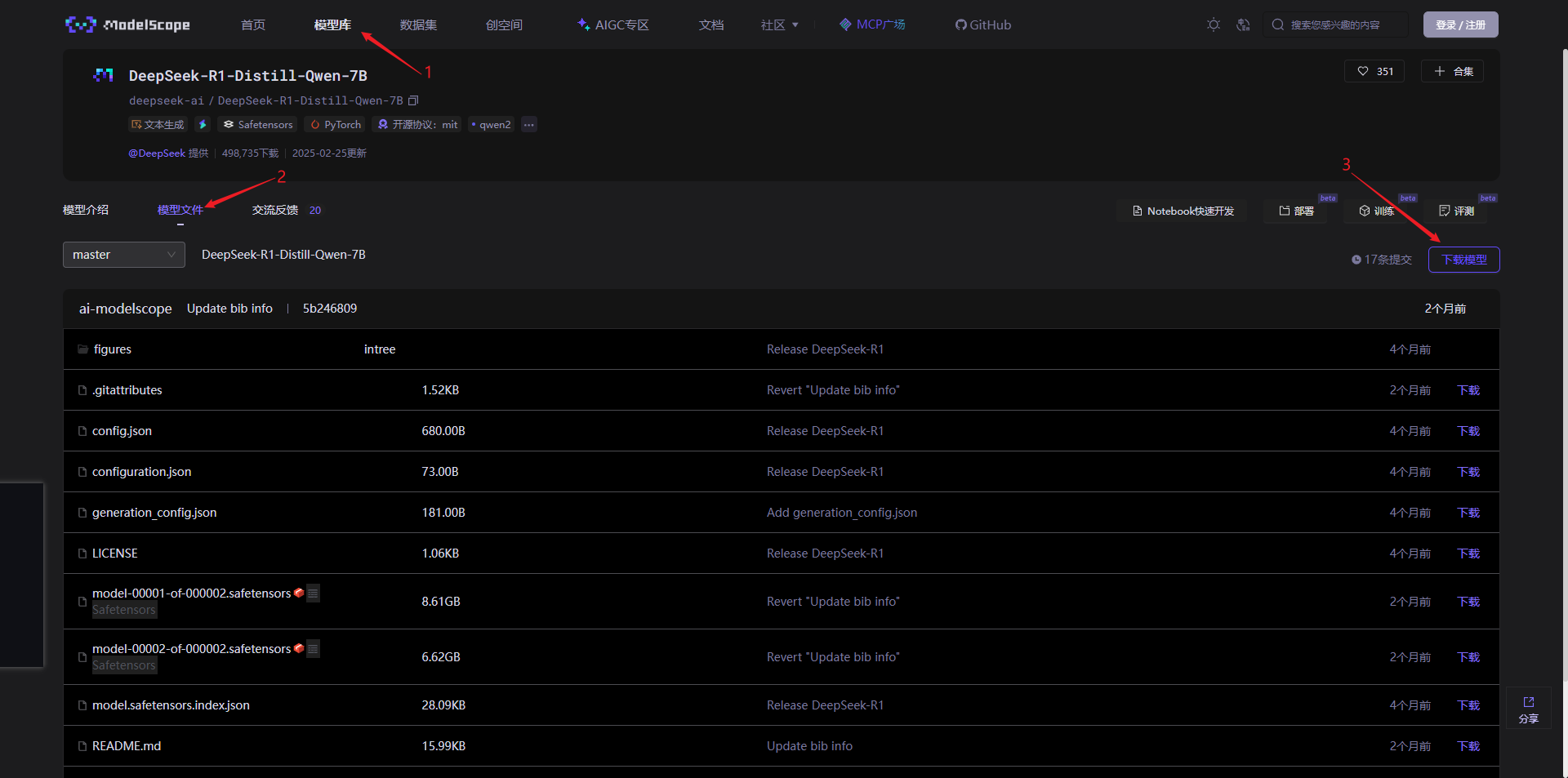
根据右侧弹出的下载提示,用 ModelScope 下载模型 DeepSeek-R1-Distill-Qwen-7B:
# 安装魔塔
pip install modelscope
# 创建模型存储目录
# 系统盘/大小为50G的需要修改,避免系统盘空间不足
# 镜像sglang_0.4.6.post5_3.10.16-ubuntu22.04_12.6中未执行此命令,已全部保存在系统盘默认存储目录中
mkdir -p /data/modelscoope
# 下载模型
# 如果用户系统盘为50G,需要将模型下载到指定名录,如:/data/modelscoope/ 目录(耗时较长 ... )
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir /data/modelscoope/DeepSeek-R1-Distill-Qwen-7B# 安装魔塔
pip install modelscope
# 创建模型存储目录
# 系统盘/大小为50G的需要修改,避免系统盘空间不足
# 镜像sglang_0.4.6.post5_3.10.16-ubuntu22.04_12.6中未执行此命令,已全部保存在系统盘默认存储目录中
mkdir -p /data/modelscoope
# 下载模型
# 如果用户系统盘为50G,需要将模型下载到指定名录,如:/data/modelscoope/ 目录(耗时较长 ... )
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir /data/modelscoope/DeepSeek-R1-Distill-Qwen-7B启动 SGLang 服务
apache
python3 -m sglang.launch_server --model-path /data/modelscoope/DeepSeek-R1-Distill-Qwen-7B --port 8890 --mem-fraction-static 0.7 --tp 1 --trust-remote-code --host 0.0.0.0python3 -m sglang.launch_server --model-path /data/modelscoope/DeepSeek-R1-Distill-Qwen-7B --port 8890 --mem-fraction-static 0.7 --tp 1 --trust-remote-code --host 0.0.0.0验证 SGLang 服务
方式一:在服务器上使用CURL发送请求:
其中:140.210.92.250为服务器公网IP,27252为内部端口8890映射的外部端口
curl -X POST http://140.210.92.250:19328/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful AI assistant"
},
{
"role": "user",
"content": "你是谁"
}
],
"temperature": 0.6,
"max_tokens": 1024
}'curl -X POST http://140.210.92.250:19328/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful AI assistant"
},
{
"role": "user",
"content": "你是谁"
}
],
"temperature": 0.6,
"max_tokens": 1024
}'得到以下输出:
{"id":"639001e14fbc475d8e6a9f69990716d0","object":"chat.completion","created":1748081142,"model":"/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B","choices":[{"index":0,"message":{"role":"assistant","content":"您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"stop","matched_stop":151643}],"usage":{"prompt_tokens":13,"total_tokens":86,"completion_tokens":73,"prompt_tokens_details":null}}{"id":"639001e14fbc475d8e6a9f69990716d0","object":"chat.completion","created":1748081142,"model":"/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B","choices":[{"index":0,"message":{"role":"assistant","content":"您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。\n</think>\n\n您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"stop","matched_stop":151643}],"usage":{"prompt_tokens":13,"total_tokens":86,"completion_tokens":73,"prompt_tokens_details":null}}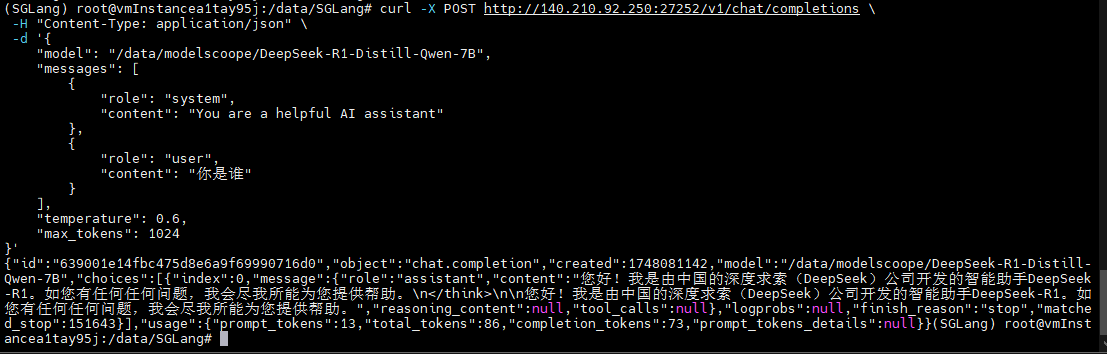
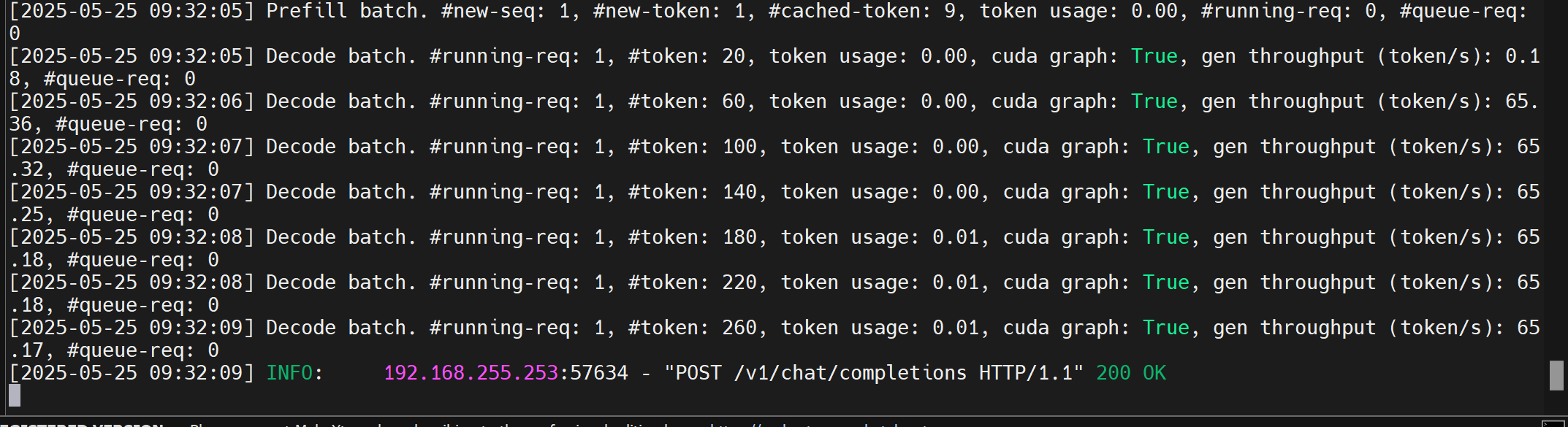
SGLang日志输出如下:
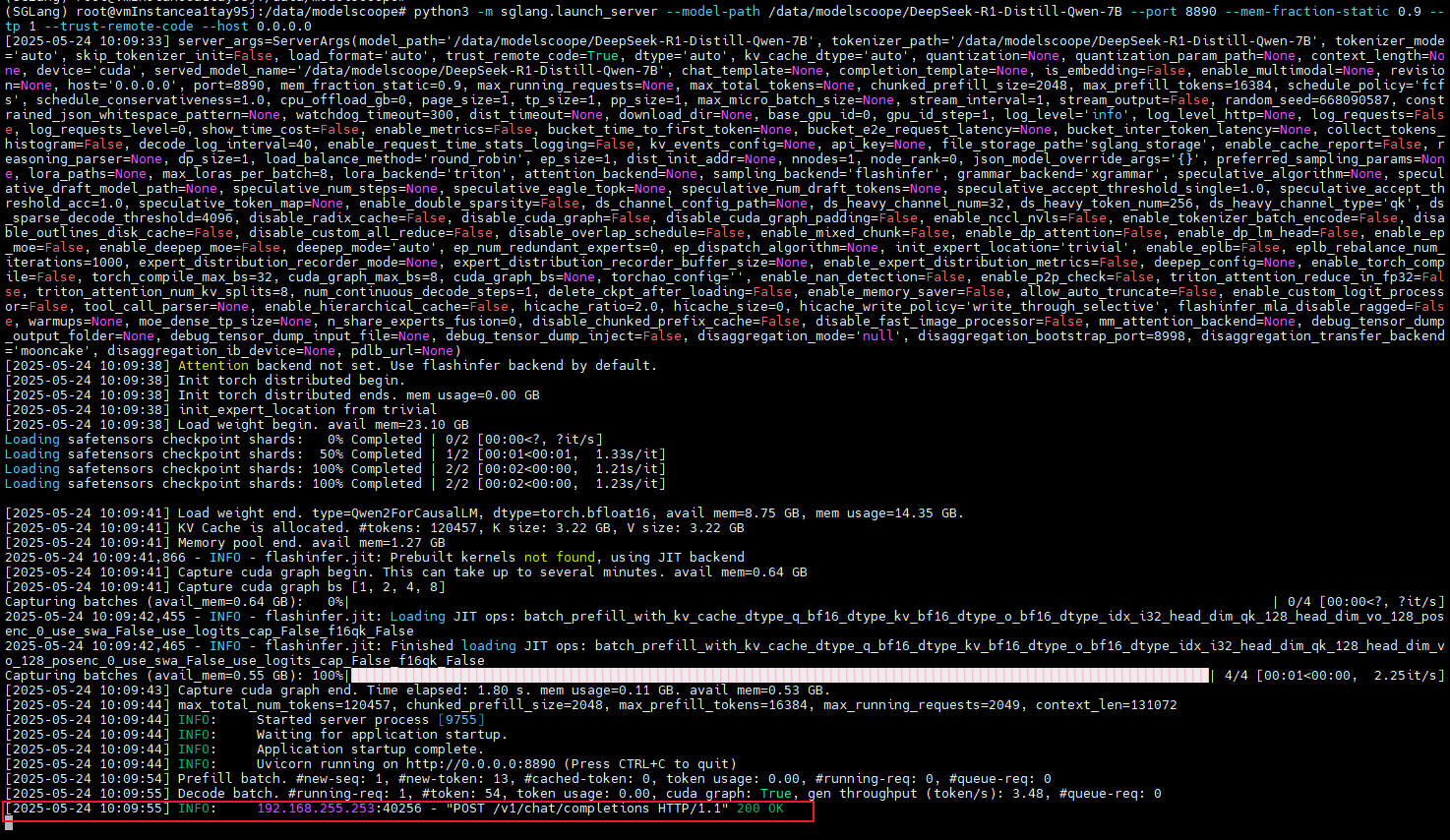
动态观察显存变化
txt
watch -d -n 0 nvidia-smiwatch -d -n 0 nvidia-smi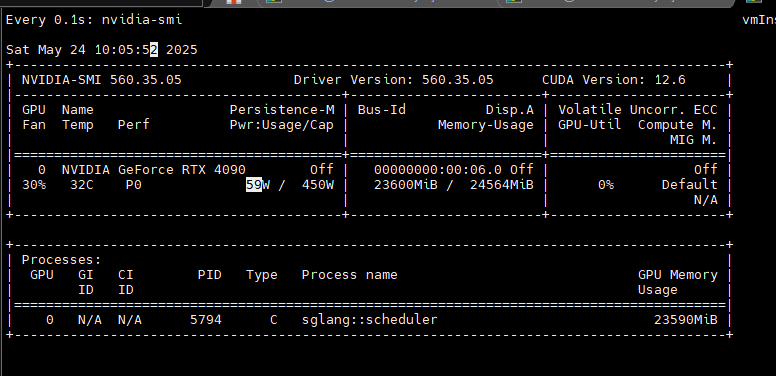
方式二:在服务器上使用 Python 发送请求
进入 python 环境
python3python3在交互式环境中运行以下 python 代码:
import requests
url = "http://140.210.92.250:27252/v1/chat/completions"
data = {
"model": "/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B",
"messages": [{"role": "user", "content": "北京春天适合去哪里玩?"}],
}
response = requests.post(url, json=data)
if response.status_code == 200:
print(response.json())
else:
print(f"Error: {response.status_code}, Response: {response.text}")import requests
url = "http://140.210.92.250:27252/v1/chat/completions"
data = {
"model": "/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B",
"messages": [{"role": "user", "content": "北京春天适合去哪里玩?"}],
}
response = requests.post(url, json=data)
if response.status_code == 200:
print(response.json())
else:
print(f"Error: {response.status_code}, Response: {response.text}")待服务器响应后,会有类似以下输出:
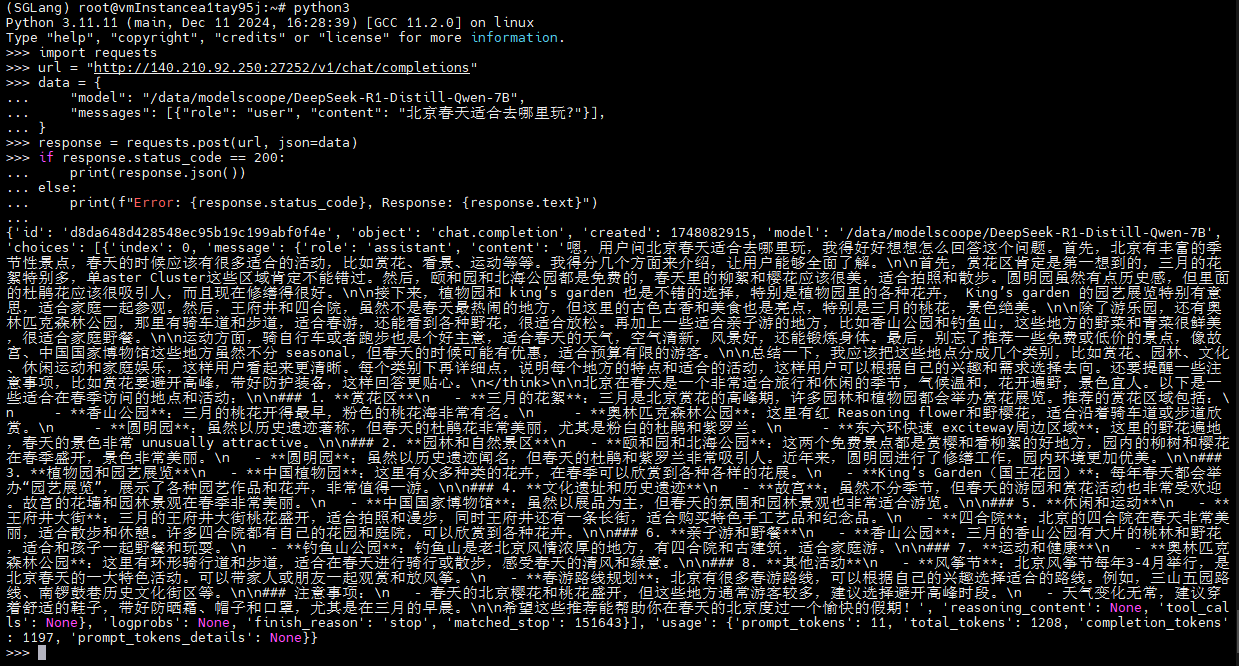
以下是部分服务器相应日志:
动态观察显存变化
txt
watch -d -n 0 nvidia-smiwatch -d -n 0 nvidia-smi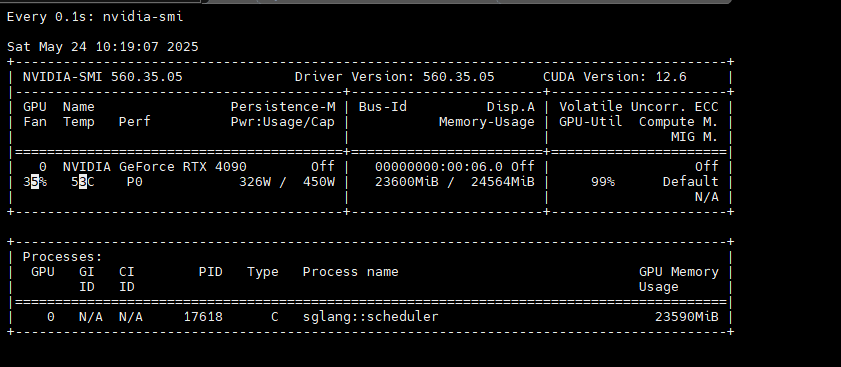
方式三:使用 OpenAI Python 客户端发送请求
将下面内容编辑成脚本OpenAI-Python-Client.sh
import openai
client = openai.Client(base_url=f"http://140.210.92.250:27252/v1", api_key="None")
response = client.chat.completions.create(
model="/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B",
messages=[
{"role": "user", "content": "推荐几个北京的景点"},
],
temperature=0,
max_tokens=256,
)
print(response)import openai
client = openai.Client(base_url=f"http://140.210.92.250:27252/v1", api_key="None")
response = client.chat.completions.create(
model="/data/modelscoope/DeepSeek-R1-Distill-Qwen-7B",
messages=[
{"role": "user", "content": "推荐几个北京的景点"},
],
temperature=0,
max_tokens=256,
)
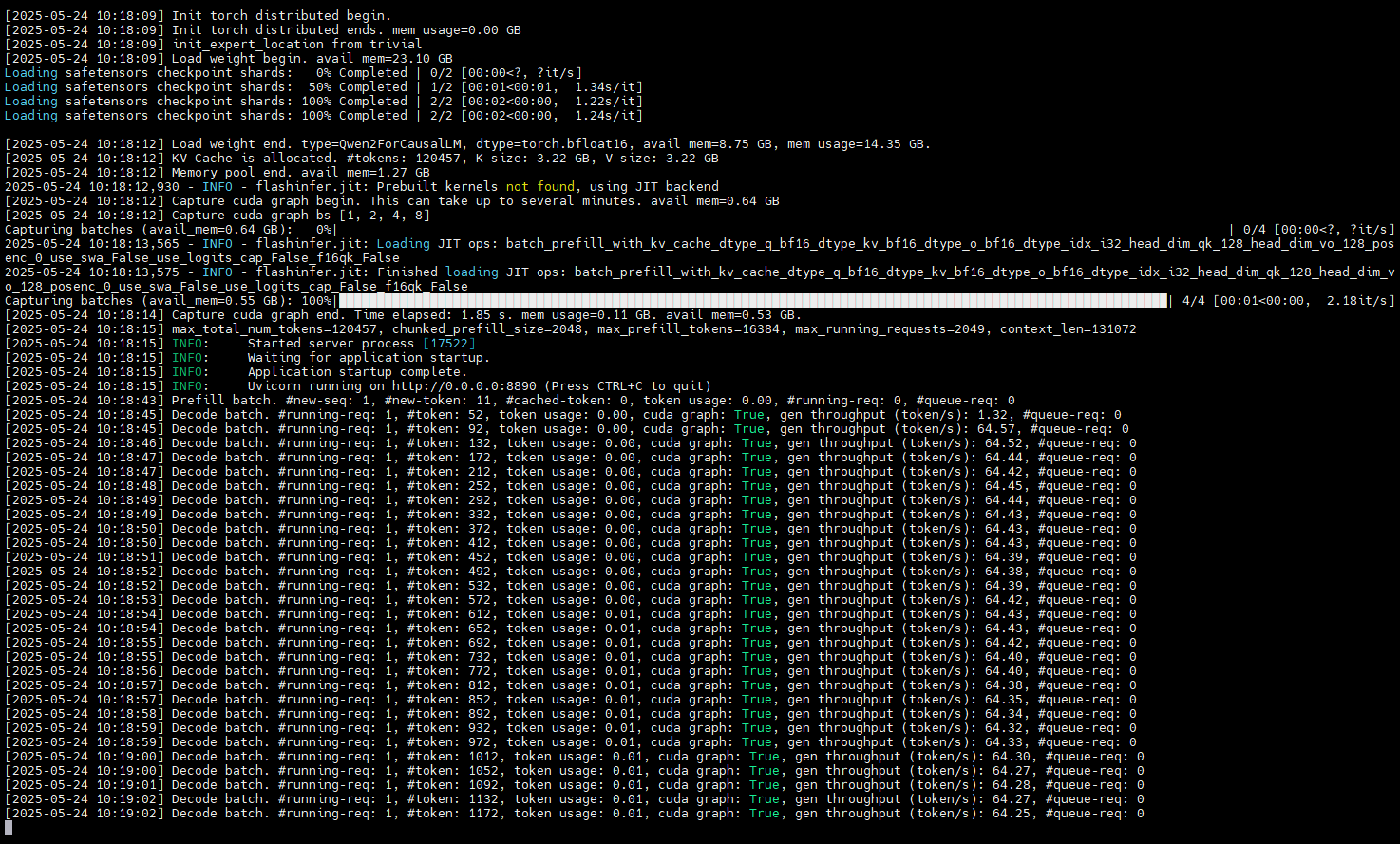
print(response)服务器响应输出:
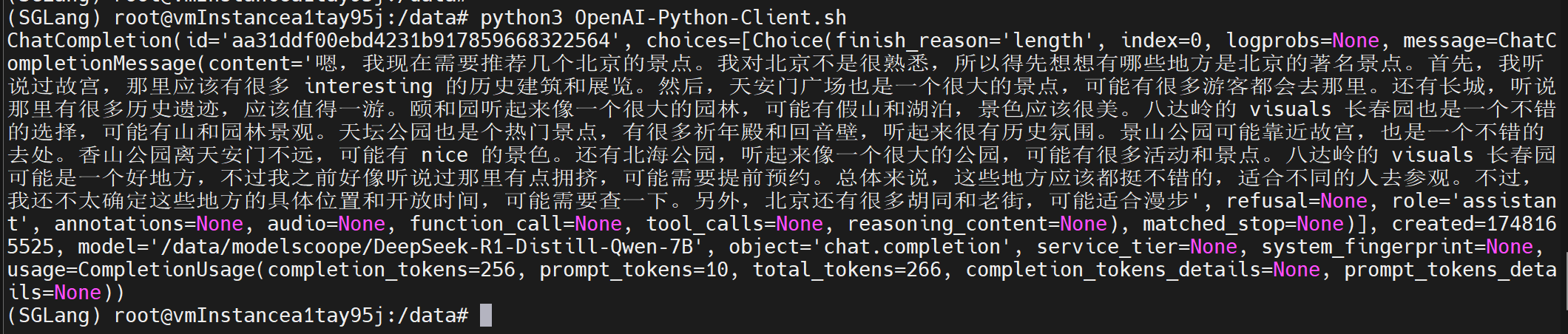
服务器相应日志: