企业级模型推理实战:Xinference跨平台部署
本教程内容已封装为
xinference_v1.6.0_3.10.16-ubuntu22.04_12.6镜像。若您使用该镜像创建云主机,可以在云主机启动完成后登录实例,通过本地直接启动Xinference服务:conda activate py311 XINFERENCE_MODEL_SRC=modelscope XINFERENCE_HOME=/data/xinference xinference-local -H 0.0.0.0 -p 8890conda activate py311 XINFERENCE_MODEL_SRC=modelscope XINFERENCE_HOME=/data/xinference xinference-local -H 0.0.0.0 -p 8890Xinference 服务默认运行在内部端口
8890。在云主机的【更多连接方式】→【预留端口】,您可通过IP及内部端口映射的公网端口实现对外访问。详情请查看文章,案例仅供参考。
Xinference 简介
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。其特点是部署快捷、使用简单、推理高效,并且支持多种形式的开源模型,还提供了 WebGUI 界面和 API 接口,方便用户进行模型部署和推理。通过 Xinference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xinference 与最前沿的 AI 模型,发掘更多可能。下面是 Xinference 与 vLLM 功能性和应用场景对比:
| 特性 | XInference | vLLM |
|---|---|---|
| 定位 | 作为一个开源的模型推理平台,支持多种推理引擎(如 Transformers、vLLM、Llama.cpp 等),适用于多种硬件环境(如 CPU、GPU 和 TPU),能够高效运行多种类型的 AI 模型,包括语言模型、嵌入模型和多模态模型。 | 作为一个高性能推理引擎,专为大型语言模型设计的高性能推理引擎 |
| 安装配置 | 均可通过 pip/docker/Kubernetes 部署。 | - |
| 模型支持 | 110+LLM 模型,以及向量、重排、语音、OCR、文生图、文生视频等。 | 80+LLM 模型,以及其它少量向量、重排模型。 |
| 性能 | 支持 vLLM 作为引擎,并支持多副本。多副本能线性扩展吞吐和降低延迟,并且共享的 KV Cache 功能大幅提升多实例情况下的性能。同时,支持 SGLang、Llama.cpp 和 MLX 等引擎满足不同平台的性能需求。 | 单一推理引擎。 |
| 成本 | 本地部署,需要本地硬件支持,成本取决于硬件配置。 | - |
| 应用场景 | 除大模型推理外,还支持多模态、文图等应用,提供分布式部署能力,适合需要灵活部署和多模型支持的场景。 | 以大模型推理为主。 |
| 易用性 | 不仅提供了终端命令行,还提供了 WebUI,方便部署和查看使用情况。 | 仅提供终端命令行。 |
| 扩展性 | 有丰富的生态,支持主流和国产显卡。 | 生态丰富,支持主流显卡。 |
安装Docker(可选)
如果使用 Docker 镜像安装Xinference,需要安装。在Ubuntu 20.04上安装Docker可以通过以下步骤完成:
更新软件包索引
打开终端并执行命令以确保你的软件包索引是最新的。
bash
sudo apt-get updatesudo apt-get update安装一些必要的软件包,以便apt能够通过HTTPS使用仓库:
bash
sudo apt-get install apt-transport-https ca-certificates curl software-properties-commonsudo apt-get install apt-transport-https ca-certificates curl software-properties-common开启学术加速
export http_proxy=http://10.132.19.35:7890
export https_proxy=http://10.132.19.35:7890export http_proxy=http://10.132.19.35:7890
export https_proxy=http://10.132.19.35:7890添加Docker的官方GPG密钥:
这一步是为了确保你从Docker下载的软件是安全可靠的。
bash
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -设置稳定的仓库:
添加Docker的APT仓库到你的系统中。
bash
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"再次更新软件包索引:
因为你刚添加了一个新的仓库,所以需要再次更新软件包索引。
bash
sudo apt-get updatesudo apt-get update从新添加的仓库中安装Docker CE:
现在你可以安装最新的Docker版本了。
bash
sudo apt-get -y install docker-cesudo apt-get -y install docker-ce验证Docker是否安装成功:
安装完成后,运行下面的命令来确认Docker已经正确安装并且可以正常工作。
bash
sudo docker --versionsudo docker --version修改docker的数据目录、配置代理及镜像源,vim /etc/docker/daemon.json
默认docker的镜像和容器存储都在/var/lib/docker目录下,如果系统盘空间较小,建议将docker数据目录调整到其他可用空间更大的目,避免系统盘空间不足。详细操作步骤请查看修改Docker数据目录。镜像源registry-mirrors地址仅供参考,自行修改。
"data-root": "/data/docker",
"registry-mirrors": [
"https://docker.1panel.live",
"https://docker.nju.edu.cn",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://registry.docker-cn.com"
],
"proxies": {
"http-proxy": "http://10.132.19.35:7890/proxy.pac",
"https-proxy": "http://10.132.19.35:7890/proxy.pac",
"no-proxy": "localhost"
}"data-root": "/data/docker",
"registry-mirrors": [
"https://docker.1panel.live",
"https://docker.nju.edu.cn",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://registry.docker-cn.com"
],
"proxies": {
"http-proxy": "http://10.132.19.35:7890/proxy.pac",
"https-proxy": "http://10.132.19.35:7890/proxy.pac",
"no-proxy": "localhost"
}重启docker
systemctl daemon-reload
systemctl restart dockersystemctl daemon-reload
systemctl restart docker查看docker 版本
docker infodocker info查看docker compose 版本
docker compose versiondocker compose version安装nvidia-docker
设置仓库和GPG密钥
bash
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listdistribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list部署 nvidia-container-toolkit 包
apt-get update
apt-get install -y nvidia-container-toolkitapt-get update
apt-get install -y nvidia-container-toolkitruntime配置
nvidia-ctk runtime configure --runtime=dockernvidia-ctk runtime configure --runtime=docker重启
systemctl restart dockersystemctl restart docker安装 Xinference
Xinference 支持两种方式的安装,一种是使用 Docker 镜像安装,另外一种是直接在本地进行安装。
官方文档:https://inference.readthedocs.io/en/latest/getting_started/installation.html
Github:https://github.com/xorbitsai/inference
前置条件
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- CUDA >= 12.4 && NVIDIA Driver >= 550
幕僚算力虚机参数:
- 镜像:conda3_25.1.1_3.10.16-ubuntu22.04_12.6
- GPU:1卡 (4090)
- 数据盘:100G(原50GB,另外扩容50GB)
Docker镜像安装Xinference
想了解 Docker 安装方式的朋友可以参考官方的Docker 安装文档。
当前,可以通过两个渠道拉取 Xinference 的官方镜像。1. 在 Dockerhub 的 xprobe/xinference 仓库里。2. Dockerhub 中的镜像会同步上传一份到阿里云公共镜像仓库中,供访问 Dockerhub 有困难的用户拉取。拉取命令:docker pull registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:<tag> 。目前可用的标签包括:
nightly-main: 这个镜像会每天从 GitHub main 分支更新制作,不保证稳定可靠。v<release version>: 这个镜像会在 Xinference 每次发布的时候制作,通常可以认为是稳定可靠的。latest: 这个镜像会在 Xinference 发布时指向最新的发布版本- 对于 CPU 版本,增加
-cpu后缀,如nightly-main-cpu。
下面我们使用 Xinference 官方的 Docker 镜像来一键安装和启动 Xinference 服务(确保你的机器上已经安装了 Docker),将 9997 端口映射到虚拟机的 8890 端口,命令如下:
# pull 镜像比较耗时,因此我先拉取镜像,再执行启动命令
docker pull xprobe/xinference:v1.6.0
docker run \
-e XINFERENCE_MODEL_SRC=modelscope \
-e XINFERENCE_HOME=/data/xinference \
-v /data/xinference:/root/.xinference \
-p 8890:9997 \
--gpus all \
xprobe/xinference:v1.6.0 \
xinference-local -H 0.0.0.0 --log-level debug# pull 镜像比较耗时,因此我先拉取镜像,再执行启动命令
docker pull xprobe/xinference:v1.6.0
docker run \
-e XINFERENCE_MODEL_SRC=modelscope \
-e XINFERENCE_HOME=/data/xinference \
-v /data/xinference:/root/.xinference \
-p 8890:9997 \
--gpus all \
xprobe/xinference:v1.6.0 \
xinference-local -H 0.0.0.0 --log-level debug
--gpus必须指定,正如前文描述,镜像必须运行在有 GPU 的机器上,否则会出现错误。-H 0.0.0.0也是必须指定的,否则在容器外无法连接到 Xinference 服务。- 可以指定多个
-e选项赋值多个环境变量。
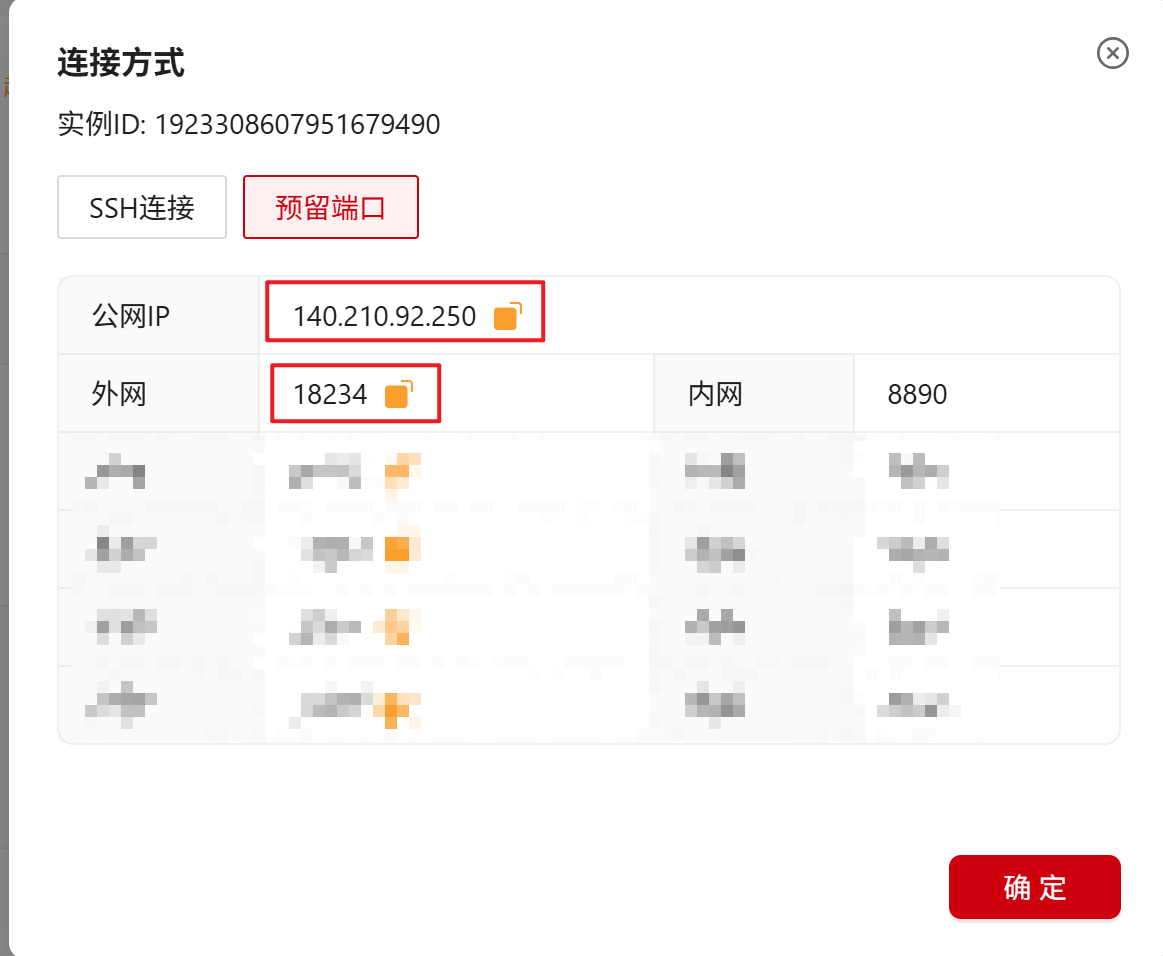
服务启动后,我们可以通过公网ip:8890的外部映射端口来访问 Xinference 的 WebGUI 界面例如:http://140.210.92.250:18234。
本地安装Xinference
首先,我们需要准备一个 3.9 以上的 Python 环境运行来 Xinference,建议先根据 conda 官网文档安装 conda。 然后使用以下命令来创建 3.11 的 Python 环境:
conda create --name py311 python=3.11
conda activate py311conda create --name py311 python=3.11
conda activate py311以下两条命令在安装 Xinference 时,将安装 Transformers 和 vLLM 作为 Xinference 的推理引擎后端:
# 修改pip缓存目录,默认在/root/.cache/pip,这个目录不能扩容,所以修改到/data/下
# 直接在终端执行,仅对当前终端会话临时有效
export PIP_CACHE_DIR=/data/pip/cache
# 验证 pip 缓存目录
pip cache dir
python3 -m pip install --upgrade pip
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
# 同时安装(本文用的这条命令)
pip install "xinference[transformers,vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
#或者一次安装所有的推理后端引擎
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple# 修改pip缓存目录,默认在/root/.cache/pip,这个目录不能扩容,所以修改到/data/下
# 直接在终端执行,仅对当前终端会话临时有效
export PIP_CACHE_DIR=/data/pip/cache
# 验证 pip 缓存目录
pip cache dir
python3 -m pip install --upgrade pip
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install "xinference[vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
# 同时安装(本文用的这条命令)
pip install "xinference[transformers,vllm]" -i https://pypi.tuna.tsinghua.edu.cn/simple
#或者一次安装所有的推理后端引擎
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simplepip 在 安装 Transformers 和 vLLM 时会自动安装 PyTorch,但自动安装的 CUDA 版本可能与你的环境不匹配,此时你可以根据 PyTorch 官网中的**安装指南[6]**来手动安装。
在安装完 Xinference 之后,可以执行以下命令看 PyTorch 是否正常:
python3 -c "import torch; print(torch.cuda.is_available())"python3 -c "import torch; print(torch.cuda.is_available())"如果输出结果为
True,则表示 PyTorch 正常,否则需要重新安装 PyTorch,PyTorch 的安装方式可以参考PyTorch 的页面。

启动 Xinference
Xinference 推理引擎后端的第三方库比较多,所以安装需要花费一些时间,等安装完成后,我们就可以启动 Xinference 服务了,启动命令如下:
xinference-local -H 0.0.0.0 -p 8890xinference-local -H 0.0.0.0 -p 8890默认情况下,Xinference 会使用
<HOME>/.xinference作为主目录来存储一些必要的信息,比如日志文件和模型文件,其中<HOME>就是当前用户的主目录。你可以通过配置环境变量
XINFERENCE_HOME修改主目录, 比如:XINFERENCE_HOME=/data/xinference xinference-local -H 0.0.0.0 -p 8890XINFERENCE_HOME=/data/xinference xinference-local -H 0.0.0.0 -p 8890Xinference 模型下载缺省是从Huggingface官方网站下载 https://huggingface.co/models 。在国内因为网络原因,可以通过下面的环境变量设计为其它镜像网站:
HF_ENDPOINT=https://hf-mirror.com.
或者直接通过环境变量"XINFERENCE_MODEL_SRC",将模型下载源设置为:ModelScope。例:
XINFERENCE_MODEL_SRC=modelscope XINFERENCE_HOME=/data/xinference xinference-local -H 0.0.0.0 -p 8890XINFERENCE_MODEL_SRC=modelscope XINFERENCE_HOME=/data/xinference xinference-local -H 0.0.0.0 -p 8890
恭喜!你已经在本地拉起了 Xinference 服务。Xinference 默认端口为 9997,这里用-p参数将服务 Xinference 端口设置为虚拟机内部端口8890。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过虚拟机的公网 IP 地址来访问 Xinference 服务。
访问 Xinference
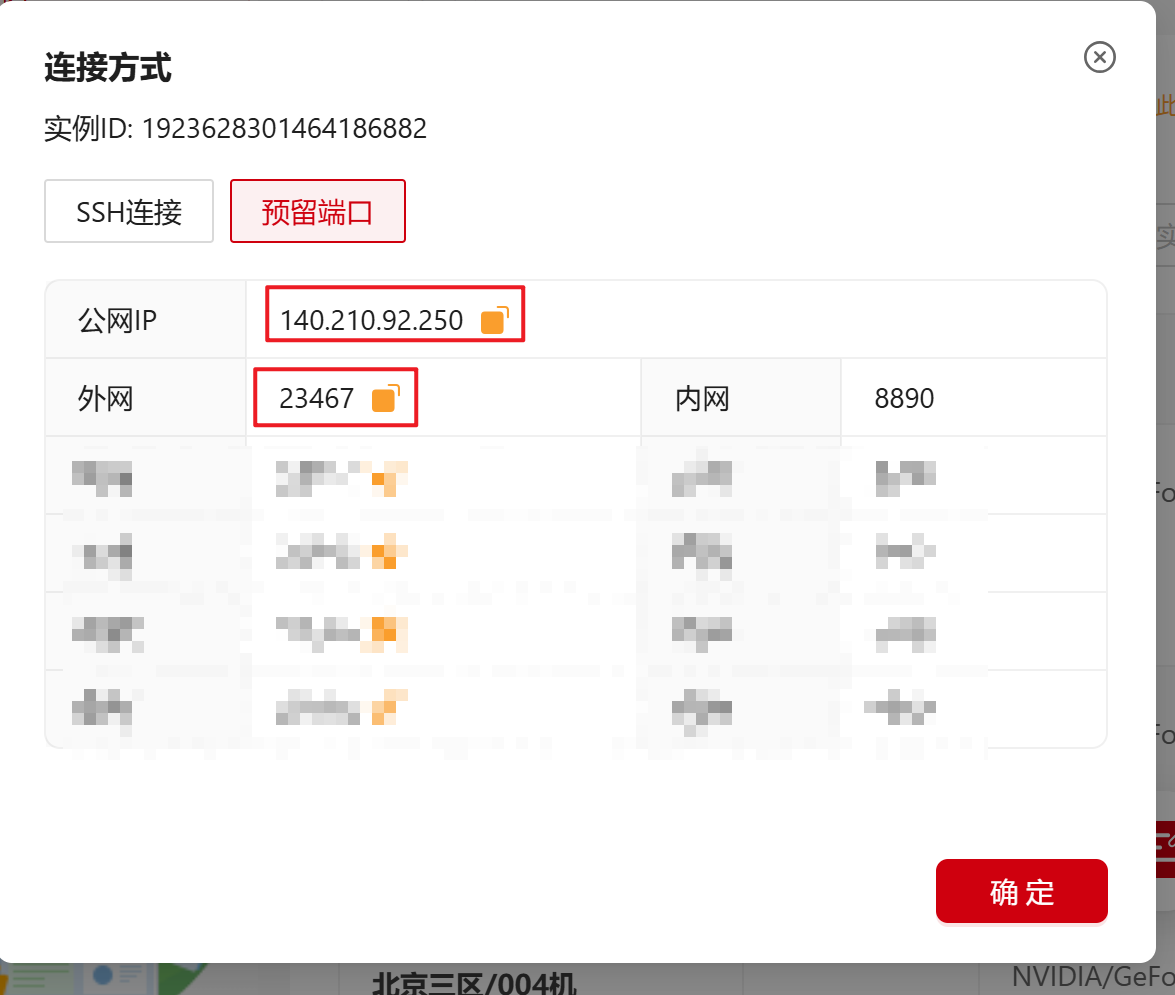
在本教程中,我们可以通过公网ip:8890的外部映射端口来访问 Xinference 的 WebGUI 界面例如:http://140.210.92.250:23467。
部署模型
部署之后的xinfrenece是长这样子的

功能说明:
- launch Model:可以发现一些内置的模型,只是这些模型需要下载才可以使用,可以直接在页面上点击下载
- Running Models:正在运行的模型
- Register Model:注册模型,可以将自己微调后的模型在这里注册
- Cluster Information:集群信息,在这里可以看到当前xinference部署的宿主机的硬件信息
内置的模型类型:
- 大语言模型
- 嵌入模型
- 图像模型
- 音频模型
- 重排序模型
- 视频模型
选择自己想用的模型后就可以开始安装了。模型安装可以通过WebGUI 界面下载,也可以通过命令行下载,下面以 qwen1.5-chat 模型为例分别介绍这两种下载方式:
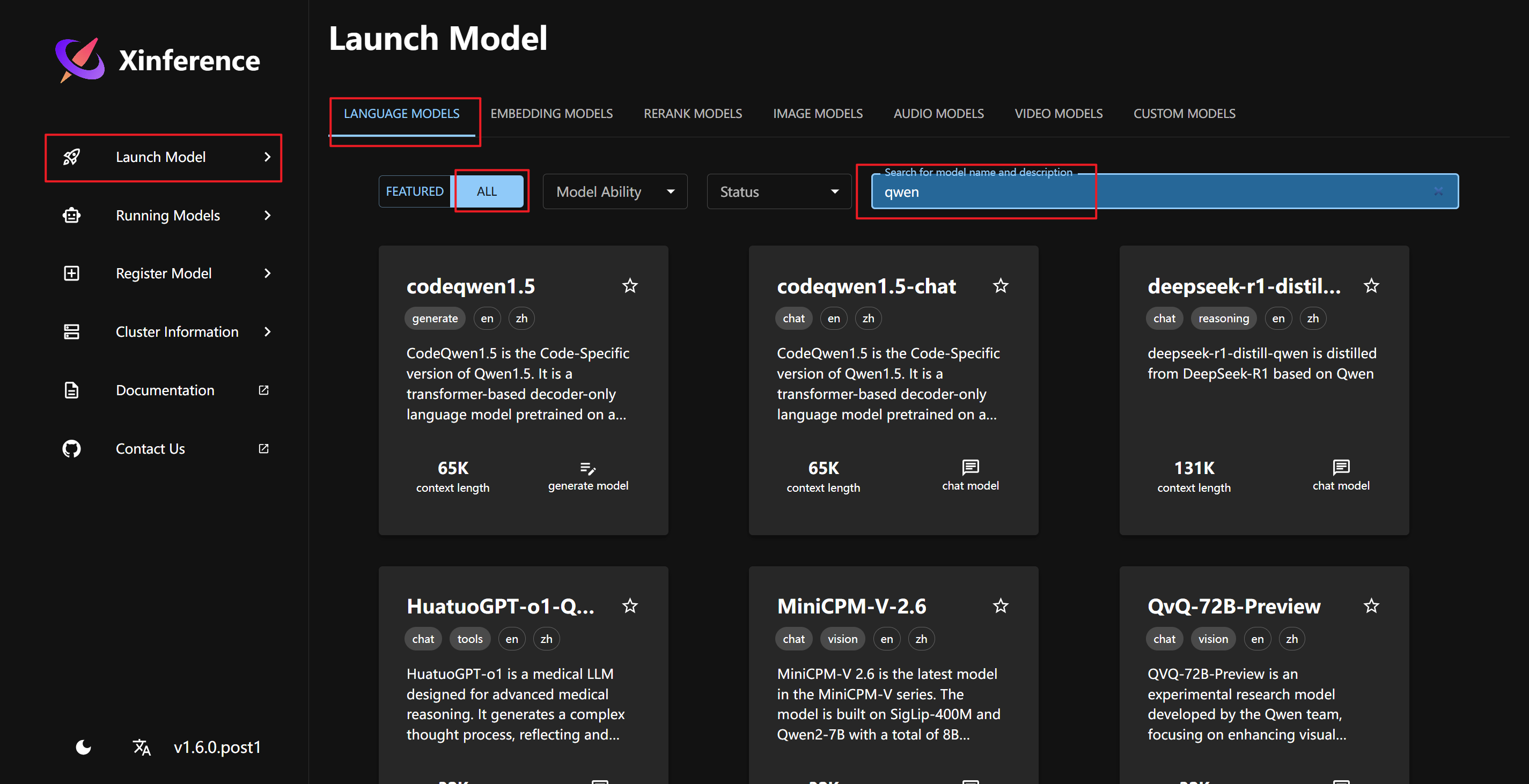
WebGUI 页面下载大语言模型
在 Xinference 的 WebGUI 界面中,我们部署模型非常简单。首先,我们在Launch Model菜单中选择LANGUAGE MODELS标签,输入模型关键字qwen来搜索我们要部署的 qwen1.5-chat 模型。
点击 qwen1.5-chat 模型,配置参数进行加载:
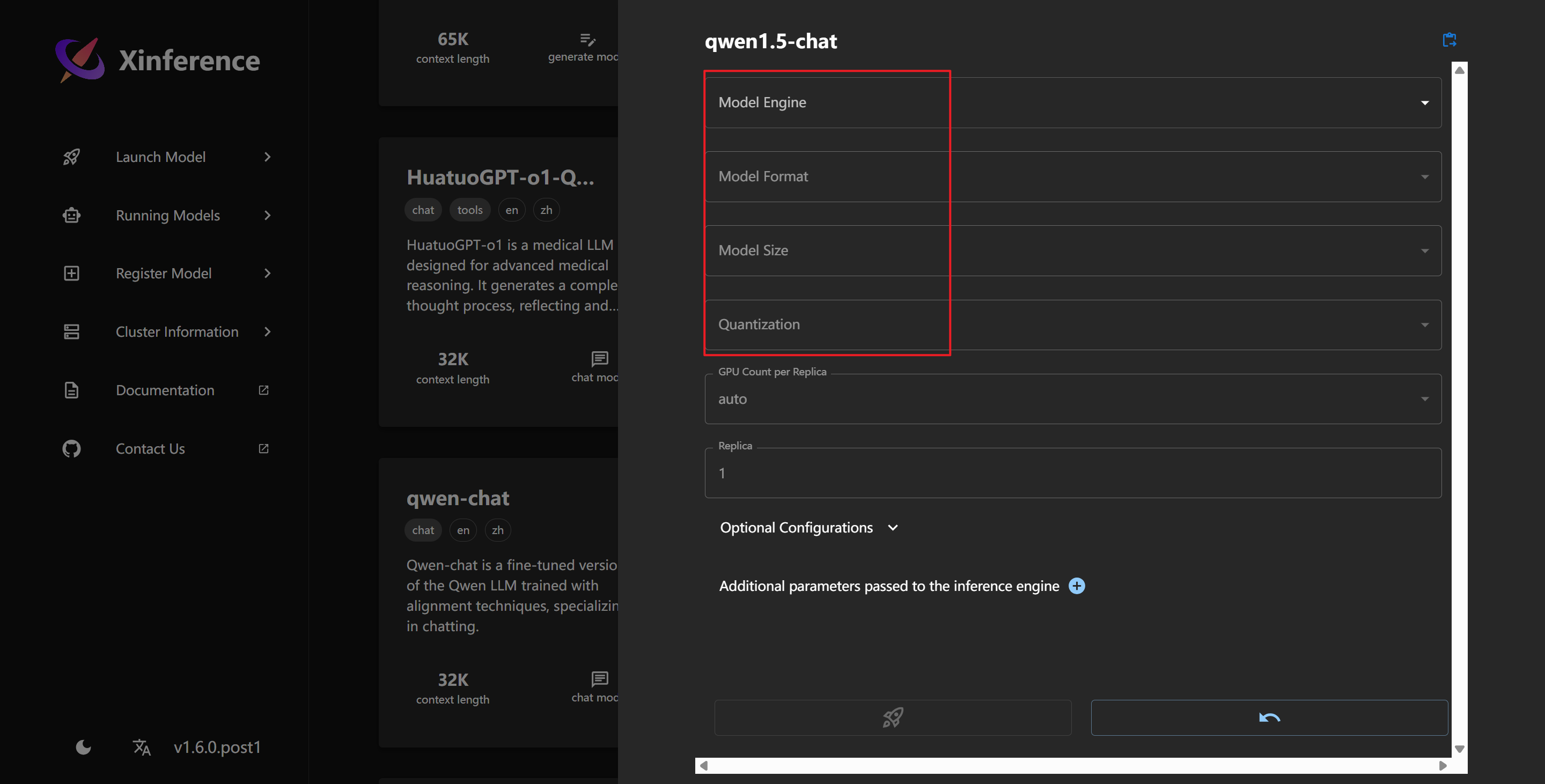
自 v0.11.0 版本开始,在加载 LLM 模型之前,你需要指定具体的推理引擎。当前,Xinference 支持以下推理引擎:
vllmsglangllama.cpptransformersMLX
关于这些推理引擎的详细信息,请参考 这里 。
注意,当加载 LLM 模型时,所能运行的引擎与 model_format 和 quantization 参数息息相关。可以使用 xinference engine 命令帮助你查询相关的参数,在此需先安装xinference
bash
# 修改pip缓存目录,默认在/root/.cache/pip,这个目录不能扩容,所以修改到/data/下
# 直接在终端执行,仅对当前终端会话临时有效
export PIP_CACHE_DIR=/data/pip/cache
# 如果你希望对所有新打开的终端会话都应用这个设置,可以将上述命令添加到你的 ~/.bashrc 文件中,然后重新加载配置文件
echo 'export PIP_CACHE_DIR=/data/pip/cache' >> ~/.bashrc
source ~/.bashrc
# 验证 pip 缓存目录
pip cache dir
# 安装 xinference
pip install xinference# 修改pip缓存目录,默认在/root/.cache/pip,这个目录不能扩容,所以修改到/data/下
# 直接在终端执行,仅对当前终端会话临时有效
export PIP_CACHE_DIR=/data/pip/cache
# 如果你希望对所有新打开的终端会话都应用这个设置,可以将上述命令添加到你的 ~/.bashrc 文件中,然后重新加载配置文件
echo 'export PIP_CACHE_DIR=/data/pip/cache' >> ~/.bashrc
source ~/.bashrc
# 验证 pip 缓存目录
pip cache dir
# 安装 xinference
pip install xinference使用 xinference engine 命令帮助你查询相关的参数组合。例如:
如果想查询与
qwen-chat模型相关的参数组合,以决定它能够怎样跑在各种推理引擎上。xinference engine -e http://192.168.255.122:8890 --model-name qwen1.5-chatxinference engine -e http://192.168.255.122:8890 --model-name qwen1.5-chat其中,使用
ip -a查询虚拟机 IP 为192.168.255.122,8890为 Xinference 服务端口。用户可根据自己实际IP更换。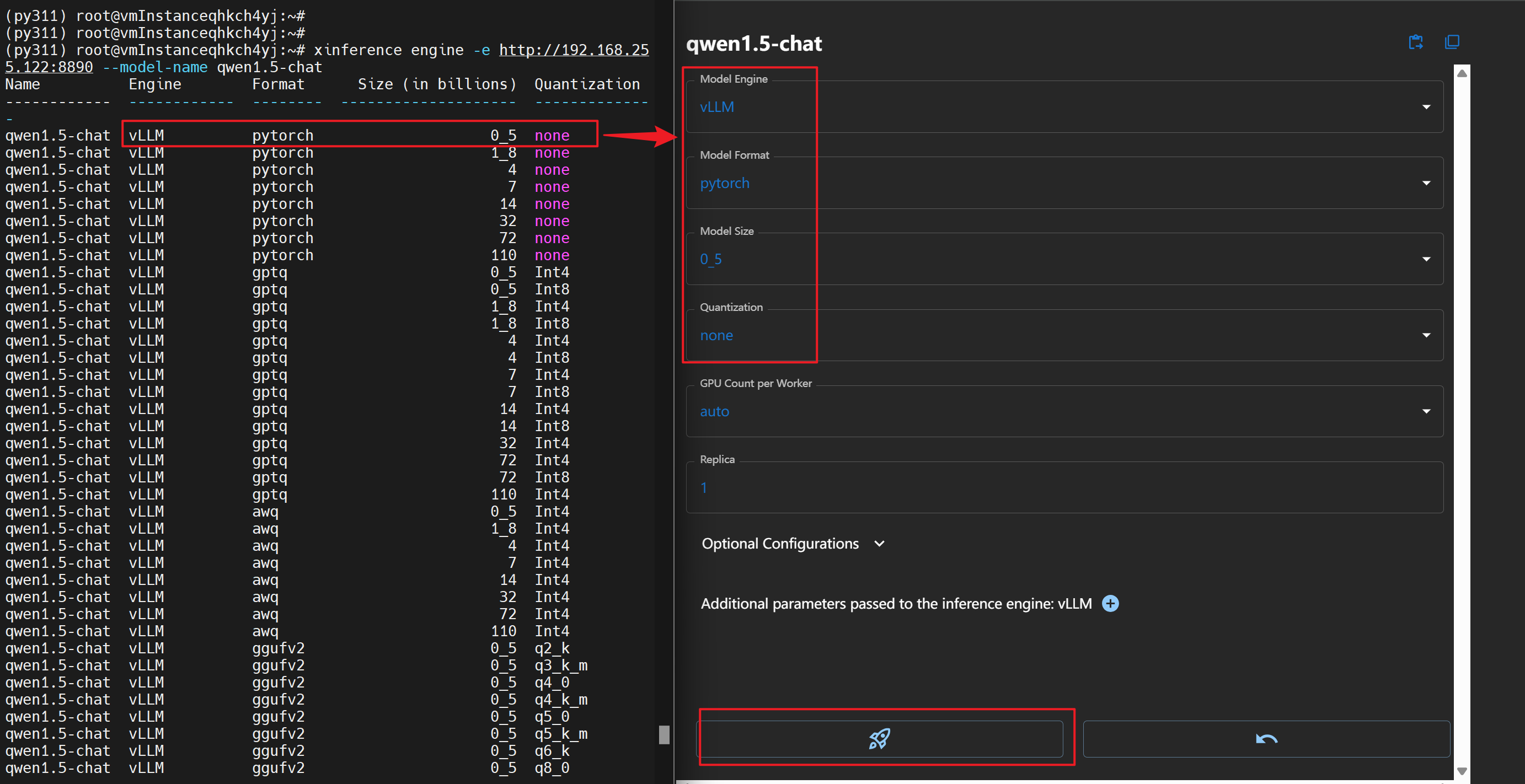
如果,我想将
qwen-chat跑在VLLM推理引擎上,但是我不知道什么样的其他参数符合这个要求。xinference engine -e http://192.168.255.122:8890 --model-name qwen1.5-chat --model-engine vllmxinference engine -e http://192.168.255.122:8890 --model-name qwen1.5-chat --model-engine vllm
总之,相比于之前的版本,当加载 LLM 模型时,需要额外传入 model_engine 参数。你可以通过 xinference engine 命令查询你想运行的推理引擎与其他参数组合的关系。
Linux关于何时使用什么引擎,以下是一些建议:
- 在能使用的情况下,优先使用 vLLM 或 SGLang,因为他们有更好的性能。
- 如果资源有限,可以考虑使用 llama.cpp,因为他提供了更多的量化选项。
- 其他使用考虑使用 Transformers,它几乎支持所有的模型。
使用命令行下载大语言模型
在 xinference 官网,找到 模型>内置模型,这是 xinference 的内置模型地址,在这里我们以大语言模型>**qwen1.5-chat (pytorch, 0_5 Billion)**为例,下载命令为:
# xinference已按照[WebGUI 页面下载大语言模型]章节安装完成
xinference launch --model-engine ${engine} --model-name qwen1.5-chat --size-in-billions 0_5 --model-format pytorch --quantization ${quantization}# xinference已按照[WebGUI 页面下载大语言模型]章节安装完成
xinference launch --model-engine ${engine} --model-name qwen1.5-chat --size-in-billions 0_5 --model-format pytorch --quantization ${quantization}在国内因为网络原因,可以直接设置环境变量XINFERENCE_MODEL_SRC=modelscope。其次,将${engine}和${quantization}参数换成用xinference engine -e http://192.168.255.122:8890 --model-name qwen1.5-chat命令所查的结果,即:
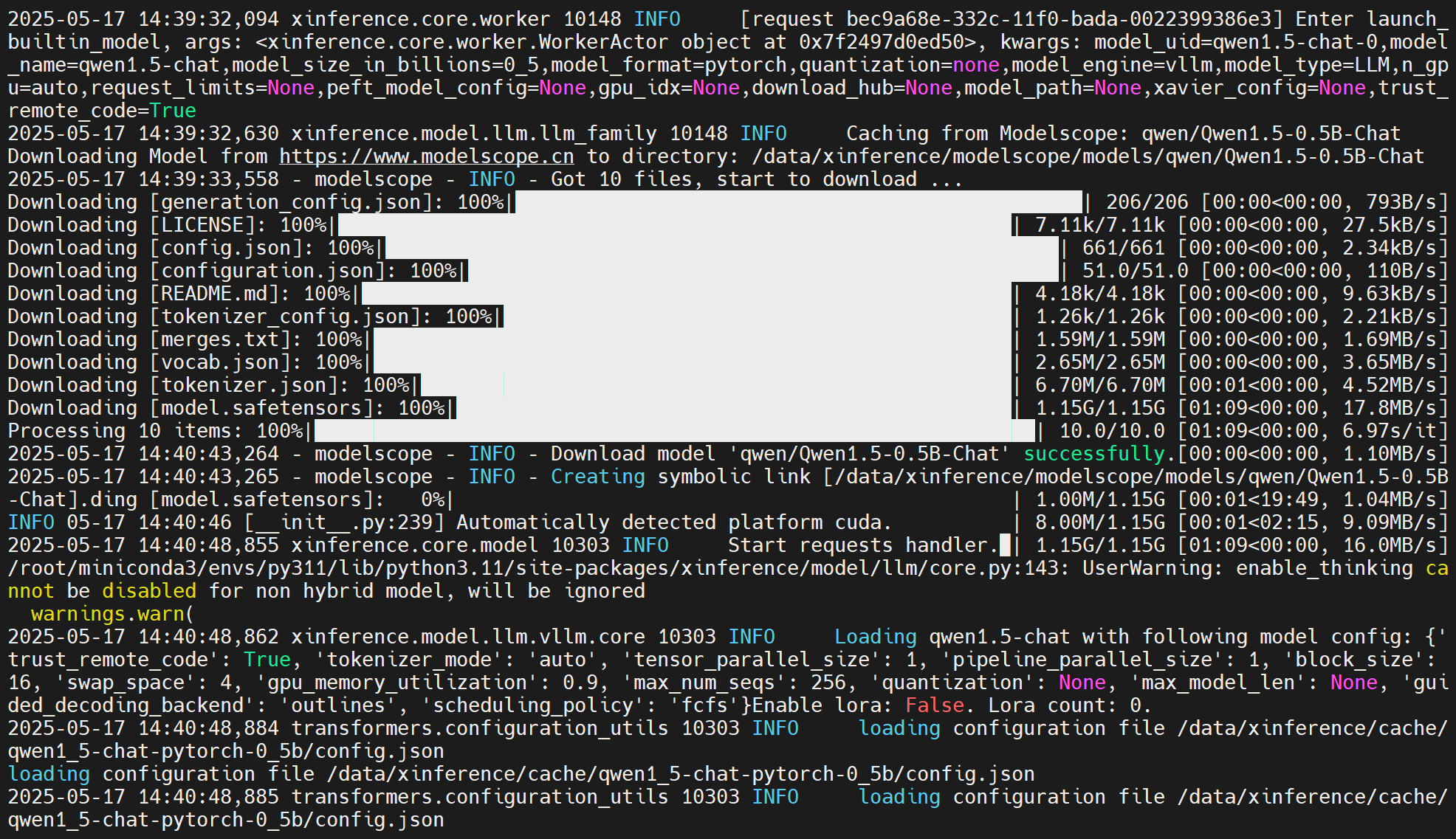
XINFERENCE_MODEL_SRC=modelscope xinference launch --model-engine vllm --model-name qwen1.5-chat --size-in-billions 0_5 --model-format pytorch --quantization none --endpoint http://0.0.0.0:8890XINFERENCE_MODEL_SRC=modelscope xinference launch --model-engine vllm --model-name qwen1.5-chat --size-in-billions 0_5 --model-format pytorch --quantization none --endpoint http://0.0.0.0:8890执行命令开始下载,执行命令页面:

xinference服务启动页面也会输出模型下载过程:
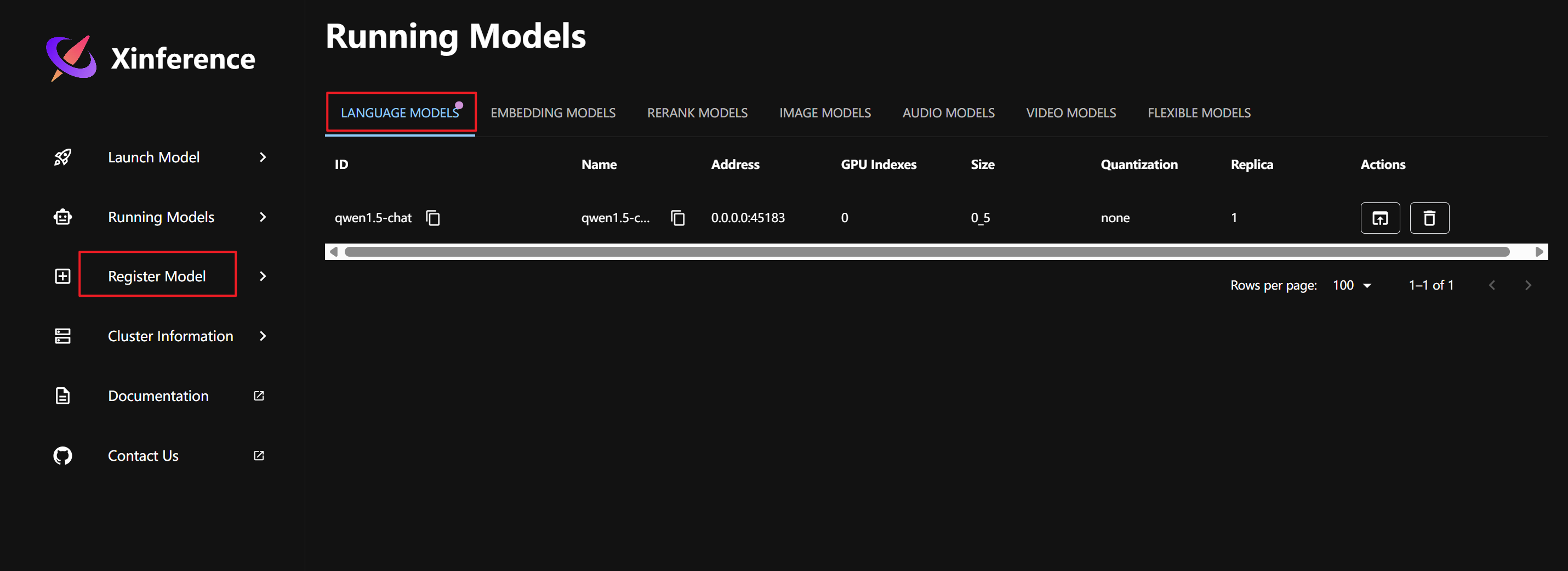
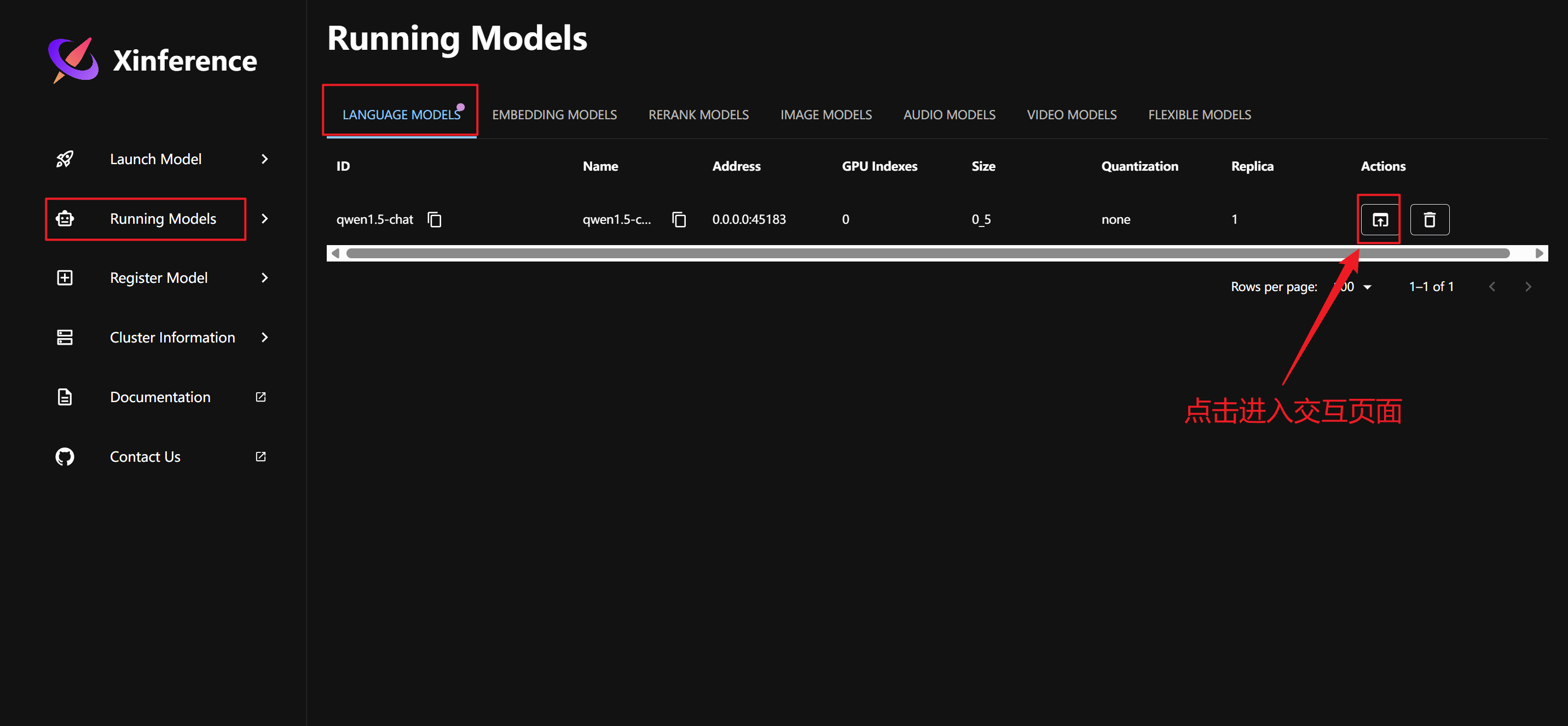
下载好后,刷新 WebGUI 页面,模型会自动加载出来:
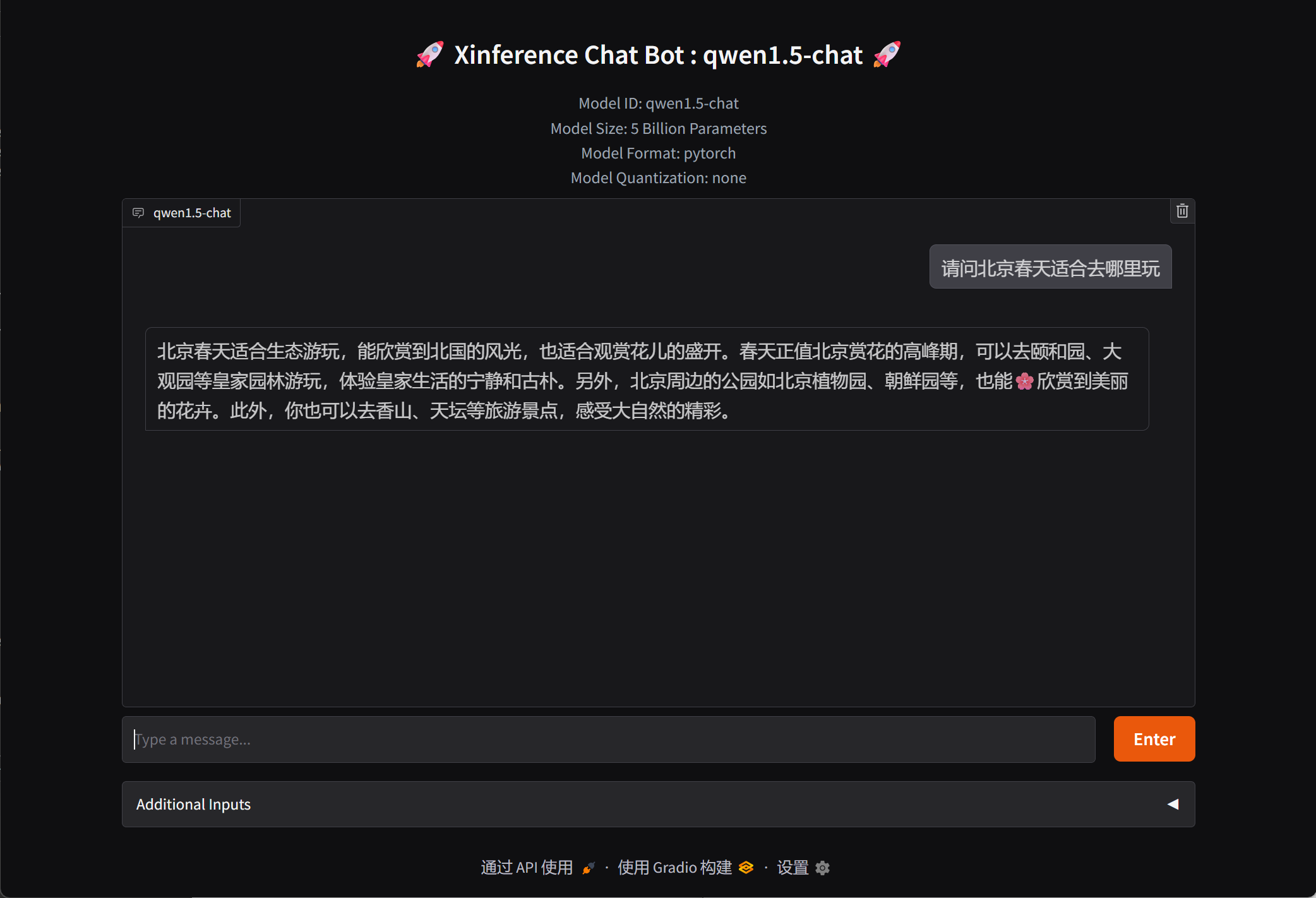
交互
到这里就可以进行交互啦!